前情提要: 昨天講了語音相關的pre-trained model,以及可以應用的場景。
今天我們來提提模型蒸餾(model distillation),蒸餾的目的是希望可以讀到一個較小的model,犧牲一點準確度來提高速度並且壓縮模型的大小,常見的名詞有teacher model, student model。
我這邊就直接翻成老師模型及學生模型,想法就是老師把他畢生所學的整理好教給學生,讓學生可以不用從頭開始研究,那這樣學生更好學習,以下我們透過一些圖及程式來講解。
參考網址: https://amit-s.medium.com/everything-you-need-to-know-about-knowledge-distillation-aka-teacher-student-model-d6ee10fe7276
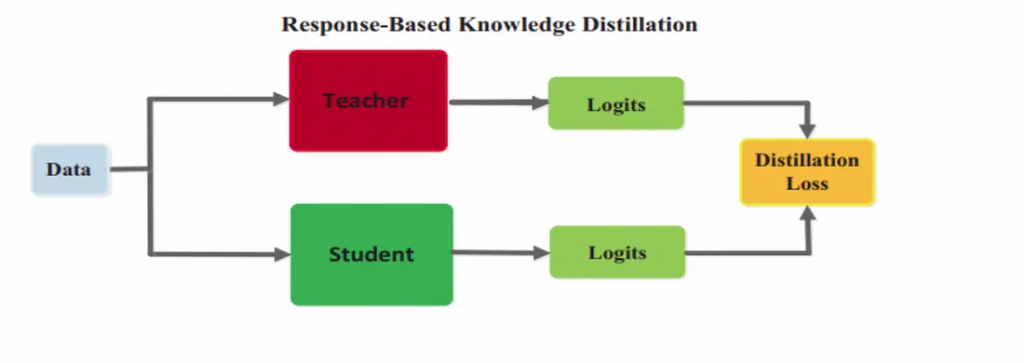
這裡的老師模型其實就是我們已經用大量資料訓練出來的pre-trained model,像之前提到的whisper, bert, wav2vec2…,那學生模型可以是相同架構但層數較少,或完全不同架構的也行,那這裡Data處理完分別送到老師及學生的模型去預測,然後Loss function是老師跟學生的logits去做的,這就是我剛才說的,學生是學老師教的,而不是從頭學起(學正確答案 label)。
github: https://github.com/huggingface/distil-whisper/blob/main/training/run_distillation.py
論文: https://arxiv.org/pdf/2311.00430
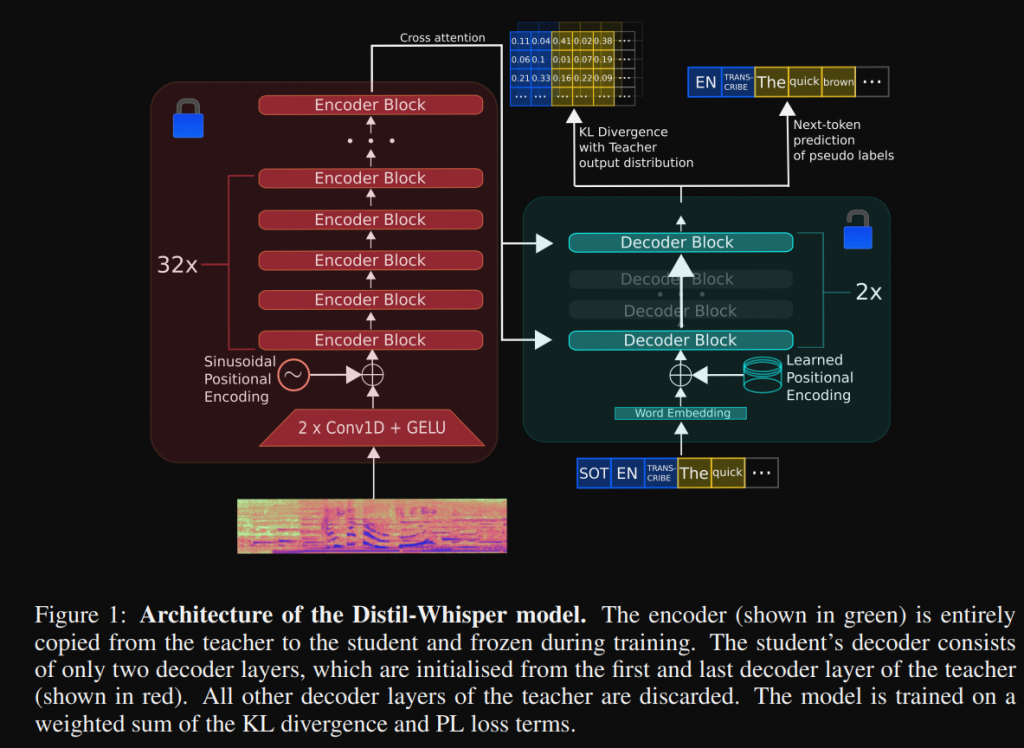
這裡我們看一個範例,在論文當中架構圖如下,把原先的whisper的encoder拿來做使用,並且凍結他的參數(不更新encoder的參數),然後decoder選兩層,在訓練的時候主要是更新這兩層參數。
在1023行主要就是凍結student encoder參數,

從1465行開始訓練的step
1470: 凍結老師模型所有參數
1472: 學生模型計算出來的結果
1478或1481: 老師模型計算出來的結果
1490: 將學生與老師的結果計算Loss
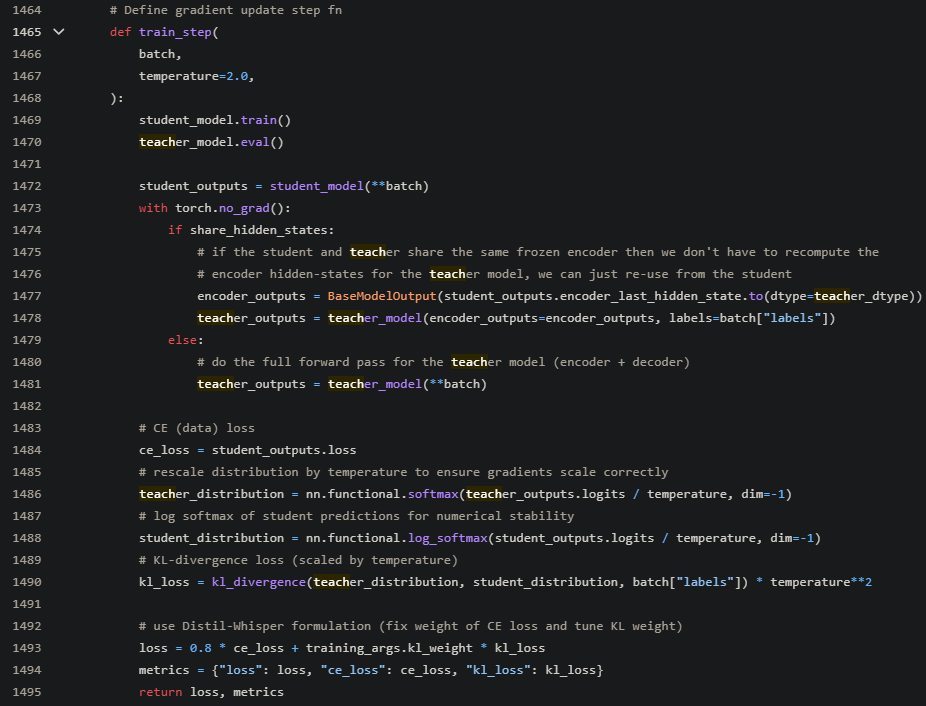
從以上這段程式,應該可以與最一開始的圖完美對應,這裡只是給個觀念,讓大家知道模型蒸餾這個詞,有興趣可以更進一步去研究論文或程式~~
最後講些觀念,因為有些觀念我知道,但沒有實際訓練過,所以不確定水有多深,只是分享名詞給碩班同學而已。
今天就先到這裡囉~


 iThome鐵人賽
iThome鐵人賽